| Pandas 输出 DataFrame 至 SQL Server | 您所在的位置:网站首页 › pandas dataframe 添加一行数据 › Pandas 输出 DataFrame 至 SQL Server |
Pandas 输出 DataFrame 至 SQL Server
|
一、to_sql 的作用 把储存在 DataFrame 里面的记录写到 SQL 数据库中。 可以支持所有被 SQLAlchemy 支持的数据库类型。 在写入到 SQL 数据库中的过程中,可以新建表,append 到表,以及覆盖表。 二、语法DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, Chunksize=None, dtype=None, method=None) 其中: name:str 类型,表示 SQL 表的名称。 con:sqlalchemy.engine.(Engine 或者 Connection) 类型 或者 sqlite3.Connection 类型。 使用 SQLAlchemy 使得我们可以使用该库支持的所有数据库。该方法也提供对 sqlite3.Connection 对象的支持,该方法已过时但因使用范围广而难以替代所以才保留了这个支持。用户应对 SQLAlchemy connectable 的引擎处理和连接关闭负责。详见这里。 schema:str 类型,可选的。 具体说明 schema(如果数据库支持这个)。如果为 None,则将使用默认 schema。 if_exists:{'fail', 'repalce', 'append'},默认值为 'fail'。 该参数指定如果一个表已经存在了应该咋整: fail:Raise 一个 ValueError。replace:在插入新的值之前 drop 这个表。append:在现寸的表里面插入新的值。index:bool 类型,默认值为 True。 将 DataFrame 的 index 写为一列。将使用 index_label 作为表中的 column name。 index_label:str 类型或者 sequence 类型,默认值为 None。 为 index column(s) 提供 column 的 label。如果本参数被设置为 None,同时前一个参数 index 被设置为 True,那么该 index 的 names 将会被使用做由 index 转化而来 的 column(s) 的名字。如果你的 DataFrame 使用了 MultiIndex,则应当提供一个 sequence。 chunksize:int 类型,可选的。 具体说明一次写入多少行的数据。默认情况下,所有的行会被一次写入。 dtype:dict 类型或者 scalar 类型,可选的。 具体说明 columns 的 datatype。如果使用字典类型,keys 应当是 columns names,values 应当是 SQLAlchemy 类型,或者字符串型(针对于 sqplite3 legacy mode 的情况)。如果我们提供了一个 scalar 类型,那么这个值会被应用到所有的 columns。 method:{None, 'multi', callable},可选的。 控制 SQL 插入语句的使用: None:使用标准的 SQL INSERT 语句(每行一个)'multi':在一个 INSERT 语句中传递多个值带有签名的 callable (pd_table, conn, keys, data_iter)在 insert method 章节里面可以了解详细信息和一个 callable 的应用样例。 三、返回值None 或者 int 类型。 被 to_sql 影响到的行的数量。 如果传递给 callable 的 method 没有返回整数的行数,则 None 会被返回。 返回的被影响的行数是 sqlite3.Cursor 或者 SQLAlchemy connectable 的 rowcount 属性的求和,根据在 sqlite3 和 SQLAlchemy 中的规定,该 rowcount 属性的求和可能不能反映被写入的行的准确数量。 四、Raises当该表已经存在并且 if_exist 参数被设定为 'fail'(默认值) 的时候,raise ValueError。 五、应用举例创建一个内存中的 SQLite 数据库。 from sqlalchemy import create_engine import pandas as pd engine = create_engine('sqlite://', echo=False)关于 SQLAlchemy 的 create_engine 怎么用,请参考我的这篇文章: 从 0 创建一个总共有 3行的表。 df = pd.DataFrame({'name' : ['User 1', 'User 2', 'User 3']}) df将 DataFrame 写入数据库 df.to_sql('users', con=engine)从数据库中提取数据 engine.execute("SELECT * FROM users").fetchall() 我们也可以将 sqlalchemy.engine.Connection 传递给 con: with engine.begin() as connection: df1 = pd.DataFrame({'name' : ['User 4', 'User 5']}) df1.to_sql('users', con=connection, if_exists='append')如果有些操作要求「相同的 DBAPI 连接被用于整个操作」,这种传递方式可以允许我们进行这类操作。 df2 = pd.DataFrame({'name' : ['User 6', 'User 7']}) df2.to_sql('users', con=engine, if_exists='append') engine.execute("SELECT * FROM users").fetchall()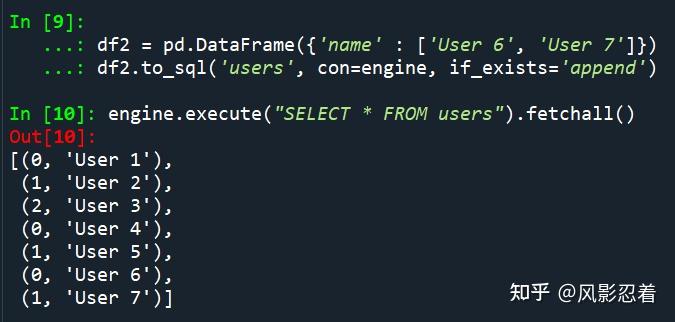 仅用 df2 覆盖整个表。 df2.to_sql('users', con=engine, if_exists='replace', index_label='id') 具体说明 dtype (对于有缺失值的整形数据特别有用)。请注意,尽管 pandas 强制将数据储存为浮点型型,数据库能够支持可为空的整型数据。当用 Python 提取数据的时候,我们得到整型的标量。 df = pd.DataFrame({"A": [1, None, 2]}) df engine.execute("SELECT * FROM integers").fetchall() engine.execute("SELECT * FROM integers").fetchall() 参考文献 |
【本文地址】